

- Датасеты ИНИД
- ЕМИСС
- Портативная СУБД с базой Росстата для исследователей и не только
- Единая межведомственная информационно-статистическая система
- Как пользоваться сервисом
- Делаем свой «клон» ЕМИСС
- Структура базы данных
- Представления
- Импорт данных в БД
- Реализация поиска
- Поиск по шаблону
- Полнотекстовый поиск
- Регистрация личного кабинета, его функционал
- Блокировки!
- Государственный статистический учет в России
- Статистика вчера и сегодня
- Единый статистический ресурс — ЕМИСС
- Реестр показателей, наиболее популярные запросы
- Итак.
- Что обозначает ЕМИСС
- Клиентская часть
- Фронтэнд
- Бэкэнд
- Модуль rsengine
- Модуль psdb
- Модуль russtat
Датасеты ИНИД
- Постановление Правительства Российской Федерации от 02.10.2006 № 595 «О федеральной целевой программе «Развитие государственной статистики России в 2007—2011 годах».
- «Зелёные» инвестиции: затраты на охрану окружающей среды в регионах РФ по классификации CEPA».
ЕМИСС
Современные страны, общество уделяют большое внимание статистике, широкому применению в повседневной практической деятельности результатов статистического анализа. Давно перестали недооценивать ее роль, влияние на регулирование всех сторон общественной жизни.
Статистические цифры дают представление о положении в той или иной отрасли, позволяют увидеть полную картину, сложившуюся в общественной сфере. Благодаря этому инструменту своевременно становятся видны любые несоответствия стандартным значениям, принимаются меры, упреждающие действия с целью улучшить ситуацию.
Портативная СУБД с базой Росстата для исследователей и не только

Единая межведомственная информационно-статистическая система
Материал из Data-in
Единая межведомственная информационно-статистическая система (ЕМИСС) — государственный информационный ресурс, объединяющий официальные государственные информационные статистические ресурсы, формируемые субъектами официального статистического учёта в рамках реализации федерального плана статистических работ.
В ЕМИСС собраны данные по 8013 показателям от 65 ведомств, из них 7468 показателей размещена в форме открытых данных. Доступ к данным предоставляется на безвозмездной основе. Зарегистрированным пользователям предлагается расширенный функционал (например, сохранение представления данных). Для экспертов ведомств доступен функционал ведения реестра показателей в рамках Федерального плана статистических работ (ФПСР), при этом набор функций может различаться у разных экспертов в зависимости от прав доступа, определённых администратором.
Как пользоваться сервисом
Официальный сайт с хорошим оформлением, довольно простой, имеет интуитивно понятную пользователю структуру.
Прежде всего отметим, что в верхней части страницы поместили строку поиска, дающую возможность быстро найти требуемый пользователю показатель.
Предусмотрена возможность расширенного поиска.
Как видно, поиск осуществляется:
• в зависимости от ведомства, которых более 60;
• тематики (категория объекта, сфера экономики, нарушения законности, иное); госпрограмм;
• порядка образования (статистическое наблюдения, фактические данные, расчетным способ).
По любым показателям, при необходимости, статистику можно получить за конкретный период. Нужно задать временной промежуток в специальном окне, указав начало и окончание (даты).
Имеются специальные фильтры по параметрам:
• сведения предоставляются с учетом исключенных на момент запроса;
• с учетом еще не утвержденных на момент запроса;
• только фактические.
На главной странице показаны самые интересующие пользователей показатели, имеющие наибольшее число запросов в определенное время. Например, в течение года или недели.
Кликнув на интересующую строку, можно ознакомится со сведениями, построить график на основании данных, сохранить в личном кабинете.
Вкладка «Инструменты» позволяет выделить только нужную часть сводного отчета, открыть или переслать его.
Меню настроек позволяет настроить работу с сайтом, как говорится, «под себя», для удобства обращения.
Можно посмотреть паспорт показателя. В нем содержатся сведения, как сложилась статистика значения (периодичность, методика расчета, кем представлена информация, иные сведения, которые важны для пользователя).
Ресурсом федстата предусмотрена возможность обратиться к эксперту, чтобы получить более подробную консультацию. Необходимо отправить обращение, для написания предусмотрено специальное поле. Обязательно указывать электронную почту для получения ответа.
Кроме статистики, можно ознакомиться с различными документами по функционированию организации.
Делаем свой «клон» ЕМИСС
При всех преимуществах «веб-морды» ЕМИСС (которая даже поддерживает контекстный поиск и позволяет выгружать датасеты в формате Excel), у нее есть несколько существенных недостатков, которые вообще присутствуют у подавляющего большинства открытых данных, доступных через веб:
- Нет возможности составления сложных запросов к базе, в том числе, агрегатных запросов к нескольким датасетам (таблицам)
- Нет четкого представления о структуре базы и иерархии таблиц, что очень важно для исследовательских целей (т.е. для ответа на вопрос «что я могу извлечь?»)
- Работа с данными требует постоянного доступа к сети (к сайту ЕМИСС)
- Возможности аналитики ограничены предоставленными веб-приложением инструментами (нет возможности конфигурации аналитических инструментов и визуализации графиков)
Поэтому у меня, конечно, возникла мысль автоматизировать получение данных с ЕМИСС, что в свою очередь привело к идее создания локальной базы данных в качестве «дубля» ЕМИСС. В сочетании с программным интерфейсом это решение лишено перечисленных выше недостатков. Совершенно инстинктивно мой выбор пал на решение на базе Python + PostgreSQL.
Структура базы данных
Я начал с того, что скачал с ЕМИСС полный перечень доступных датасетов (ссылку приводил выше), а также несколько самих датасетов в формате XML. Подробное описание данных ЕМИСС вы можете прочитать в вышеуказанном Руководстве пользователя, а я лишь приведу граф структуры БД, полученный на основе анализа этих XML (картинка кликабельна).
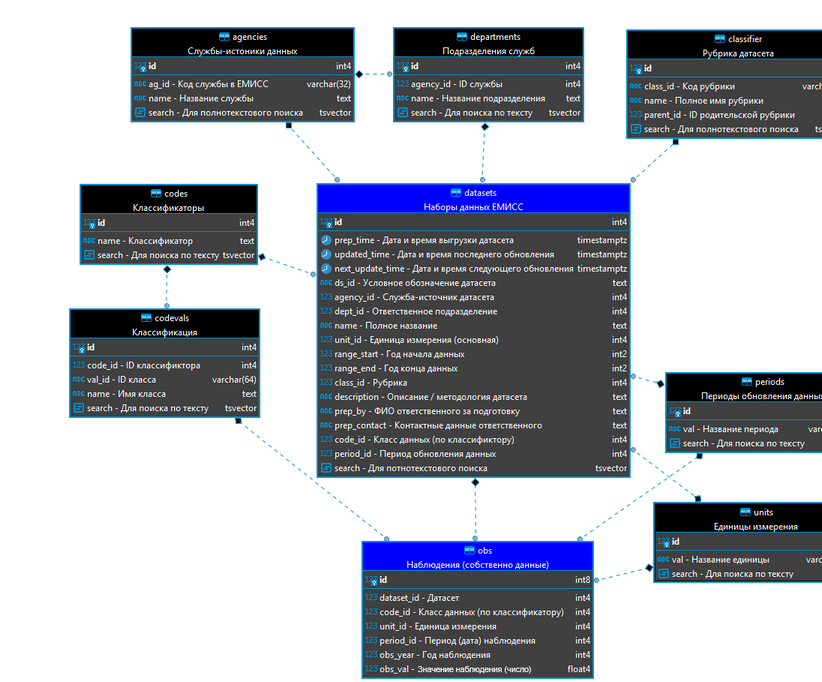
Как вы видите, структура довольна типична для реляционных БД, что, с одной стороны, повышает читаемость и надежность, а с другой стороны, добавляет гибкость, позволяя при необходимости вносить изменения в одну часть БД, не затрагивая другие.
Собственно данные (т.е. численные наблюдения по годам, кварталам и т.д.) находятся в таблице obs (“observations”), которая связана внешними ключами с таблицей датасетов (datasets), классификаций (codevals), единиц измерений (units) и периодов наблюдений (periods).
Таблица датасетов, содержащая информацию о наборах данных, связана с таблицами служб (agencies), подразделений (departments), рубрик (classifier), классификаторов (codes), единиц измерений (units) и периодов наблюдений (periods).
Остальные таблицы являются служебными, и мы не будем на них подробно останавливаться.
Представления
Специально для удобства выгрузки данных в читаемом виде (с раскрытием зависимостей между таблицами) я создал несколько представлений:
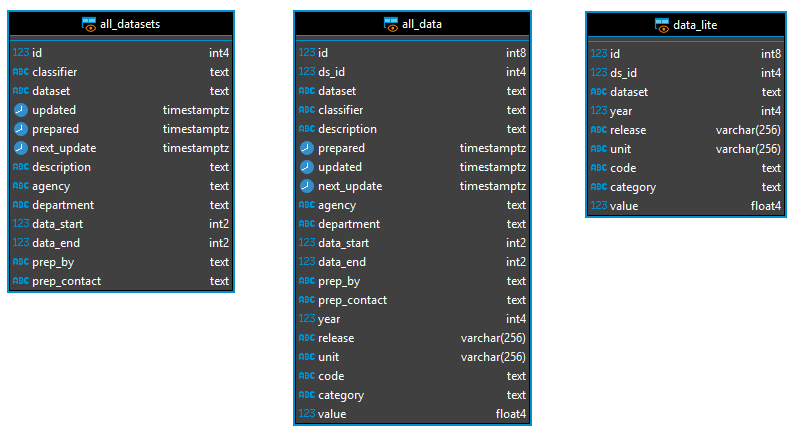
Представление all_datasets, как явствует из названия, выводит информацию обо всех датасетах в таблице datasets, с отображением данных из связанных служебных таблиц. Например, чтобы вывести первые 10 датасетов (с валидными данными — об этом дальше), выполним:
SELECT * FROM all_datasets WHERE data_start > 0 LIMIT 10;
Чтобы получить сами данные (наблюдения за определенные периоды), используется представление all_data, которое объединяет таблицу obs со всеми связанными с ней.
SQL код представления all_data (если кому интересно)
CREATE OR REPLACE VIEW public.all_data
AS SELECT obs.id,
ds.id AS ds_id,
ds.name AS dataset,
cls.name AS classifier,
ds.description,
ds.prep_time AS prepared,
ds.updated_time AS updated,
ds.next_update_time AS next_update,
ag.name AS agency,
dept.name AS department,
ds.range_start AS data_start,
ds.range_end AS data_end,
ds.prep_by,
ds.prep_contact,
obs.obs_year AS year,
per.val AS release,
units.val AS unit,
codes.name AS code,
codevals.name AS category,
obs.obs_val AS value
FROM obs
JOIN datasets ds ON obs.dataset_id = ds.id
JOIN classifier cls ON ds.class_id = cls.id
JOIN agencies ag ON ds.agency_id = ag.id
JOIN departments dept ON ds.dept_id = dept.id
JOIN periods per ON obs.period_id = per.id
JOIN units ON obs.unit_id = units.id
JOIN codevals ON obs.code_id = codevals.id
JOIN codes ON codevals.code_id = codes.id
ORDER BY cls.name, ds.name, codes.name, codevals.name, obs.obs_year, per.val;
Первые 10 наблюдений:
SELECT * FROM all_data LIMIT 10;
Наконец, поскольку представление all_data довольно тяжеловесное, так как серверу необходимо выполнить множество вложенных запросов, я создал «облегченный» вариант — представление data_lite, в котором гораздо меньше выводимых полей.
SQL код представления data_lite (меньше полей = меньше подзапросов)
CREATE OR REPLACE VIEW public.data_lite
AS SELECT DISTINCT obs.id,
ds.id AS ds_id,
ds.name AS dataset,
obs.obs_year AS year,
per.val AS release,
units.val AS unit,
codes.name AS code,
codevals.name AS category,
obs.obs_val AS value
FROM obs
JOIN datasets ds ON obs.dataset_id = ds.id
JOIN periods per ON obs.period_id = per.id
JOIN units ON obs.unit_id = units.id
JOIN codevals ON obs.code_id = codevals.id
JOIN codes ON codevals.code_id = codes.id
ORDER BY obs.obs_year, per.val, codes.name, codevals.name;
Именно эти представления используются в клиентской части для получения данных из БД. Но для того, чтобы их получить, надо сначала данные загрузить 🙂
Импорт данных в БД
Для импорта данных в базу я решил нагрузить серверную часть. Поэтому были написаны две взаимосвязанные серверные функции:
- add_dataset — для загрузки датасетов (в таблицу datasets и, при необходимости, связанные с ней)
- add_data — для загрузки наблюдений (в таблицу obs и, при необходимости, связанные с ней)
Исходный код функции add_dataset
CREATE OR REPLACE FUNCTION public.add_dataset(
prep_time timestamp with time zone, -- дата/время выгрузки датасета
last_updated timestamp with time zone, -- дата/время последнего обновления датасета
next_update timestamp with time zone, -- дата/время следующего обновления датасета
ds_id text, -- краткое условное обозначение в ЕМИСС
fullname text, -- полное название
agency_id text, -- код службы - источника данных (обычно число)
agency_name text, -- название службы - источника данных
agency_dept text, -- ответственное подразделение в службе
codes jsonb, -- классификаторы (в формате JSONB)
unit text, -- основная единица измерения (например, "человек")
periodicity text, -- периодичность данных (например, "ежеквартально")
this_release text, -- период данного выпуска (например, "I-II квартал")
data_range integer[], -- начальный и конечный год наблюдений (2 значения)
description text, -- описание методологии датасета
classifier_id text, -- код рубрики
classifier_path text, -- полный путь рубрики
prep_by text, -- ФИО ответственного за подготовку
prep_contacts text) -- контактные данные ответственного за подготовку
RETURNS integer
LANGUAGE plpgsql
AS $function$
declare
ag_id_ integer;
dept_id_ integer;
class_id_ integer;
units_id_ integer;
periods_id_ integer;
codes_id_ integer;
codename text;
js_codeval jsonb;
ds_id_ integer;
begin
-- вставляем или обновляем данные в agencies (служба)
insert into agencies(ag_id, name)
values (agency_id, agency_name)
on conflict on constraint agencies_unique1 do
update set name = excluded.name, ag_id = excluded.ag_id
returning id into ag_id_;
-- вставляем или обновляем данные в departments
insert into departments(agency_id, name)
values (ag_id_, agency_dept)
on conflict on constraint depts_unique1 do
update set name = excluded.name
returning id into dept_id_;
-- вставляем или обновляем данные в classifier
insert into classifier(class_id, name)
values (classifier_id, classifier_path)
on conflict on constraint classifier_unique1 do
update set name = excluded.name
returning id into class_id_;
-- вставляем или обновляем данные в units
insert into units(val) values (unit)
on conflict on constraint units_unique do
update set val = excluded.val
returning id into units_id_;
-- вставляем или обновляем данные в periods
insert into periods(val) values (periodicity)
on conflict on constraint periods_unique do
update set val = excluded.val
returning id into periods_id_;
-- вставляем или обновляем данные в codes
-- {'code_id': {'name': 'code_name', 'values': [['val_id', 'name'], [...], ...]}, {...}, ...}
for codename in select * from jsonb_object_keys(codes)
loop
insert into codes(name) values (codes->codename->>'name')
on conflict on constraint codes_unique1 do
update set name = excluded.name
returning id into codes_id_;
for js_codeval in select * from jsonb_array_elements(codes->codename->'values')
loop
insert into codevals(code_id, val_id, name)
values (codes_id_, js_codeval->>0, js_codeval->>1)
on conflict on constraint codevals_unique do
update set name = excluded.name;
end loop;
end loop;
-- вставляем или обновляем данные в datasets
insert into datasets(prep_time, updated_time, next_update_time,
ds_id, agency_id, dept_id, name, period_id,
unit_id, range_start, range_end, class_id,
description, prep_by, prep_contact, code_id)
values (prep_time, last_updated, next_update,
ds_id, ag_id_, dept_id_, fullname, periods_id_,
units_id_, data_range[1], data_range[2], class_id_,
description, prep_by, prep_contacts, codes_id_)
on conflict on constraint datasets_unique1 do
update set prep_time = excluded.prep_time, updated_time = excluded.updated_time,
next_update_time = excluded.next_update_time, ds_id = excluded.ds_id,
agency_id = excluded.agency_id, dept_id = excluded.dept_id,
name = excluded.name, period_id = excluded.period_id, unit_id = excluded.unit_id,
range_start = excluded.range_start, range_end = excluded.range_end,
class_id = excluded.class_id, description = excluded.description,
prep_by = excluded.prep_by, prep_contact = excluded.prep_contact, code_id = excluded.code_id
returning id into ds_id_;
return ds_id_;
end;
$function$
;
Здесь все должно быть очевидным: на вход функции подаются значения для всех полей таблицы datasets (например, полное название датасета, дата последнего обновления, ФИО ответственного и т.д.) и связанных внешних таблиц (например, название ответственной службы, подразделения, рубрика и т.д.). СУБД последовательно обновляет сначала внешние таблицы, а затем таблицу datasets, добавляя в нее как исходные данные, так и новые значения внешних ключей. Функция возвращает ID добавленного или обновленного датасета.
А вот с функцией add_data немного по-другому: исходные данные в нее передаются как текст в формате JSON, а уже преобразование и извлечение полей данных происходит в самой функции. Это связано, с одной стороны, с желанием упростить вызов функции из клиента (любой клиент может сформировать исходные данные в виде JSON-строки), а с другой стороны, с богатыми возможностями непосредственной работы с JSON в самом Postgres (к слову, у меня версия 13 на локальном хосте).
Исходный код функции add_data
CREATE OR REPLACE FUNCTION public.add_data(
dataset_json text, -- данные в формате JSON (текст)
time_format text DEFAULT 'YYYY-MM-DD HH24-MI-SS'::text, -- исходный формат дат
OUT n_added integer, -- ВОЗВРАЩАЕМ кол-во добавленных / обновленных записей
OUT last_data_id bigint, -- ВОЗВРАЩАЕМ ID последней записи в obs
OUT dataset_id integer) -- ВОЗВРАЩАЕМ ID соответствующего датасета в datasets
RETURNS record
LANGUAGE plpgsql
AS $function$
declare
data_json jsonb;
prep_time timestamp with time zone;
last_updated timestamp with time zone;
next_update timestamp with time zone;
data_rec json;
codes_id integer;
codevals_id integer;
units_id integer;
periods_id integer;
cnt1 bigint;
cnt2 bigint;
r text;
begin
n_added := 0;
last_data_id := -1;
dataset_id := -1;
data_json := dataset_json::jsonb;
prep_time := to_timestamp(data_json->>'prepared', time_format);
last_updated := to_timestamp(data_json->>'updated', time_format);
next_update := to_timestamp(data_json->'periodicity'->>'next', time_format);
-- добавить / обновить датасет
select into dataset_id public.add_dataset(prep_time, last_updated, next_update,
data_json->>'id', data_json->>'full_name',
data_json->>'agency_id', data_json->>'agency_name',
data_json->>'agency_dept', data_json->'codes',
data_json->>'unit', data_json->'periodicity'->>'value',
data_json->'periodicity'->>'releases',
array[cast(data_json->'data_range'->>0 as integer),
cast(data_json->'data_range'->>1 as integer)],
data_json->>'methodology',
data_json->'classifier'->>'id',
data_json->'classifier'->>'path',
data_json->'prepared_by'->>'name',
data_json->'prepared_by'->>'contacts');
if dataset_id = -1 then
raise notice '! Unable to add or update dataset!';
return;
end if;
-- добавить наблюдения
select count(*) into cnt1 from obs;
for data_rec in select * from jsonb_array_elements(data_json->'data')
loop
-- code
begin
select id into strict codes_id from codes
where lower(name) = lower(data_rec->>0) limit 1;
exception
when NO_DATA_FOUND then
insert into codes(name) values (data_rec->>0)
on conflict on constraint codes_unique1 do
update set name = excluded.name
returning id into codes_id;
end;
-- codeval
begin
select id into strict codevals_id from codevals
where code_id = codes_id and lower(name) = lower(data_rec->>1) limit 1;
exception
when NO_DATA_FOUND then
insert into codevals(code_id, name) values (codes_id, data_rec->>1)
on conflict on constraint codevals_unique do
update set code_id = excluded.code_id, name = excluded.name
returning id into codevals_id;
end;
-- unit
begin
select id into strict units_id from units
where lower(val) = lower(data_rec->>2) limit 1;
exception
when NO_DATA_FOUND then
insert into units(val) values (data_rec->>2)
on conflict on constraint units_unique do
update set val = excluded.val
returning id into units_id;
end;
-- period
begin
select id into strict periods_id from periods
where lower(val) = lower(data_rec->>3) limit 1;
exception
when NO_DATA_FOUND then
insert into periods(val) values (data_rec->>3)
on conflict on constraint periods_unique do
update set val = excluded.val
returning id into periods_id;
end;
-- вставка / обновление записи
insert into obs(dataset_id, code_id, unit_id, period_id, obs_year, obs_val)
values (dataset_id, codevals_id, units_id, periods_id,
cast(data_rec->>4 as integer), cast(data_rec->>5 as real))
on conflict on constraint obs_unique1 do
update set dataset_id = excluded.dataset_id, code_id = excluded.code_id,
unit_id = excluded.unit_id, period_id = excluded.period_id,
obs_year = excluded.obs_year, obs_val = excluded.obs_val
returning id into last_data_id;
end loop;
select count(*) into cnt2 from obs;
n_added := cnt2 - cnt1;
end;
$function$
;
Итак, все, что теперь надо сделать в клиентской части, — это подготовить исходные данные в формате JSON-строки и передать эту строку на вход функции add_data (вместе с форматом дат, который можно оставить по умолчанию), а она уже сама добавит необходимые данные во все связанные таблицы БД и выдаст количество добавленных записей, ID датасета и ID последнего добавленного наблюдения. Cool! Но что у нас с поиском по базе?
Реализация поиска
Поиск по шаблону
Для обычного параметрического поиска используем стандартные SQL-запросы к представлениям и полагаемся на скорость движка Postgres. Например, посмотрим на пассажирооборот автобусов с 2010 по 2018 гг. по стране, выведя годовые показатели:
select * from data_lite
where
dataset like 'Пассажирооборот автобусов%' and
category like 'Российская%' and
release like '%за год' and
year between 2010 and 2018
order by year;
Этот запрос у меня выполняется в среднем за 20 мс. Тот же запрос из представления all_data — за 20-30 мс (то есть примерно за такое же время). Более сложные запросы дают время выполнения все равно менее секунды, что очень хорошо для довольно объемной базы (на настоящее время у меня 1.4 млн. записей в obs).
- Чтобы искать без учета регистра, можно использовать оператор ILIKE (или его сокращенное обозначение — “~~*”).
- Чтобы искать по сложным шаблонам, можно использовать регулярные выражения и операторы поиска (NOT) SIMILAR TO, SUBSTRING, (!)~, (!)~*, REGEXP_MATCH(ES) и т.д.
Для тех же, кто более подробно хочет ознакомиться с шаблонным поисков в PostgreSQL, есть отличная документация на русском языке в переводе российской компании PostgresPro. (Хочу также обратить внимание на интересный блог этой компании на Хабре.)
Хорошо, с параметрическим поиском понятно. А как быть, если мы хотим по всей базе поискать что-то вроде «школы и детские сады» или «автобус трамвай поезд» (то есть так, как мы обычно «гуглим» в сети)? Для этого есть полнотекстовый поиск.
Полнотекстовый поиск
Как говорится в справочной документации, обычный поиск по шаблону не имеет возможности определять словоформы (т.е. не найдет строку со словом «трамваев» при поиске по слову «трамвай»), а также не позволяет упорядочить результаты поиска по релевантности (как это делают сетевые поисковые системы) и потенциально выполняется медленнее из-за отсутствия индексации.
Я не буду здесь вдаваться в подробности и терминологию полнотекстового поиска в Postgres — можете углубиться в эту тему самостоятельно, если вы с ней не очень хорошо знакомы. Мы же сразу перейдем к практике.
Итак, для реализации полнотекстового поиска по базе (наподобие того, что делает Google, Yandex, Bing и иже с ними) во все таблицы, имеющие текстовые поля, добавлено поле search, содержащее поисковые индексированные данные для поиска. Тип данных этого поля — tsvector. Также для всех таких таблиц созданы соответствующие индексы в БД (в Postgres есть два вида поисковых индексов, я использую GIN как наиболее оптимальный). Например, создание индекса для таблицы agencies выглядит так:
-- индекс GIN в таблице agencies на поле search
CREATE INDEX agencies_search_idx ON public.agencies USING gin (search)
Чтобы индексы постоянно обновлялись при обновлении данных в таблицах, используются триггерные функции для соответствующих таблиц, вызываемые при обновлении / добавлении данных. Например, для таблицы datasets определена функция datasets_update_insert:
CREATE OR REPLACE FUNCTION public.datasets_update_insert()
RETURNS trigger
LANGUAGE plpgsql
AS $function$
begin
new.description := public.entity2char(trim(replace(new.description, ' ', ' ')));
new.search := setweight(to_tsvector('russian', coalesce(new.name, '')), 'A') ||
setweight(to_tsvector('russian', coalesce(new.description, '')), 'B');
return new;
end;
$function$
;
Обратите внимание на этот пример: поле search обновляется из двух объединенных векторов (индексов) — название датасета и описание методологии, причем первый из них (название) имеет более высокий приоритет поиска (ему присваивается вес «A»). Таким образом, релевантность результатов поиска будет выше для совпадений в поле name, чем для совпадений в поле description. Также обратите внимание на явное указание локали «russian» для функции векторизации (Postgres и так бы справился, применив системную локаль, но так более наглядно и надежно). Внутренние механизмы морфологического парсера действуют исходя из заданной локали (языка), именно поэтому в БД с русскими текстами движок будет «понимать», что «трамвай» и «трамваями» имеют одну основу. А в английском языке таким же образом будут объединены, например, слова «John» и «John’s» или «read» и «reading».
Для упрощения полнотекстовых запросов я реализовал также 4 вспомогательные функции-утилиты:
- search_datasets: ищет по датасетам с использованием функции to_tsquery, где ключевые слова объединяются вручную при помощи операторов & (И), | (ИЛИ),! (НЕ) и <-> (ПРЕДШЕСТВУЕТ) и группируются скобками
- search_datasets_web: ищет по датасетам с использованием функции websearch_to_tsquery, где ключевые слова объединяются интуитивно при помощи пробелов (И), а также оператора OR (ИЛИ) или могут группироваться кавычками для обозначения строгого порядка слов (как при поиске в Интернете)
- search_data: то же, что и search_datasets, но ищет по датасетам и наблюдениям
- search_data_web: то же, что и search_datasets_web, но ищет по датасетам и наблюдениям
Больше о различиях между этими и другими функциями поиска можете прочитать в справке.
1. Ищем «школы и детские сады» в датасетах (любые совпадения слов «школа» и словосочетания «детский сад»)
-- Вариант 1) "человеческий" запрос, как в Яндексе
select * from search_datasets_web('школы "детские сады"');
-- Вариант 2) ручное форматирование
select * from search_datasets('школы & (детские <-> сады)');
2. Ищем «уголовное дело» и «Верховный Суд» в наблюдениях за 2018 год (показатели за год)
-- Вариант 1) "человеческий" запрос, как в Яндексе
select * from search_data_web('"уголовное дело" "верховный суд"')
where obsyear = 2018 and obsperiod ~~* '%за год';
-- Вариант 2) ручное форматирование
select * from search_data('уголовное <-> дело & верховный <-> суд')
where obsyear = 2018 and obsperiod ~~* '%за год'
В каждом примере показаны оба варианта: «веб-поиск» (search_*_web) и поиск с ручным форматированием ключевых слов (search_*). Результаты поиска в обоих вариантах будут идентичными.
С точки зрения вывода результатов все эти функции работают также одинаково: к возвращаемым результатам добавляется столбец ranking, который отражает ранг (релевантность) каждого результата в виде числа от 0 до 1 (чем выше, тем более релевантен результат). Результаты возвращаются по умолчанию отсортированными по этому столбцу (по убыванию), так что наиболее релевантные будут сверху.
Конечно, можно обойтись и без этих самописных функций-утилит, выполняя запросы вручную. Это может пригодиться, если требуется дополнительные степени свободы, например, указать конкретно что и как должно быть найдено в определенных таблицах и как объединять и сортировать результаты. Например, выведем наблюдения, для которых в соответствующих датасетах содержится слово «стоимость» (естественно, со всеми возможными словоформами), причем только для Российской Федерации в целом (исключая фразы типа «столица Российской Федерации») и только за весь год:
select ds.name "Датасет", ds.description "Описание", obs.obs_year "Год",
periods.val "Период", units.val "Единица", codes.name "Рубрика",
codevals.name "Категория", obs.obs_val::numeric "Значение",
ts_rank(ds.search, to_tsquery('russian', 'стоимость')) "Ранг"
from datasets ds
join obs on ds.id = obs.dataset_id
join periods on obs.period_id = periods.id
join units on obs.unit_id = units.id
join codevals on obs.code_id = codevals.id
join codes on codevals.code_id = codes.id
where
ds.search @@ to_tsquery('russian', 'стоимость') and
codevals.search @@ websearch_to_tsquery('russian', '"Российская Федерация" -столица') and
periods.search @@ to_tsquery('russian', 'год|январь-декабрь')
order by "Ранг" desc, "Датасет" asc, "Год" asc;
Результат запроса (первые 10 записей)
Кроме перечисленных «фишек», в БД еще есть несколько служебных серверных функций, на которых здесь не будем останавливаться. Во всем остальном это — стандартная реляционная БД Postgres. Конечно, ее можно и дальше оптимизировать: создавать пользовательские домены (т.е. типы данных), внедрять дополнительные функции проверки данных и вешать их на триггеры, но все это уже дело будущего. А пока посмотрим на клиентскую часть.
Регистрация личного кабинета, его функционал
- Для удобства работы пользователя на сайте предусмотрена возможность создания личного кабинета. В нем можно:
- избрать интересующие показатели;
- сохранять предоставленные данные;
- при необходимости получать обновления по интересующему вопросу.
• прописные английские символы (A—Z);
• строчные буквы (a—z);
• цифры (0—9).
Для завершения регистрации на электронную почту будет отправлено письмо, из которого следует перейти по указанной ссылке для подтверждения.
В личном кабинете имеются соответствующие инструменты для удобства работы.
Блокировки!
Апдейт
Поскольку Росстат мой IP заблокировал после обнаружения активности «бота» (хотя нигде на сайте ЕМИСС положений о таком ограничении нет), предупреждение всем, кто хочет использовать этот или иной подобный скрипт. Используйте соответствующие методы обхода IP блокировки.
Государственный статистический учет в России
Статистика вчера и сегодня
Статистические данные по нашей стране собираются довольно давно: экономические, социальные и иные показатели собирались и публиковались еще при царской власти, затем более масштабно — при советской власти и, наконец, в XXI веке (особенно с переходом на электронные базы данных) российская статистика окончательно приобрела свои современные очертания. В России сбором и обработкой статистических данных занимается Федеральная служба государственной статистики, она же просто Росстат. Своей основной целью эта служба называет «удовлетворение потребностей органов власти и управления, средств массовой информации, населения, научной общественности, коммерческих организаций и предпринимателей, международных организаций в разнообразной, объективной и полной статистической информации».
Вот как Росстат описывает становление современного статистического учета в Российской Федерации:
Начало ХХI века ознаменовалось для российской статистики принципиальными событиями. Прежде всего, в этот период были заложены единые основы осуществления официального статистического учета, которые были установлены Федеральным законом “Об официальном статистическом учете и системе государственной статистики в Российской Федерации”, принятым 29 ноября 2007 г. (далее – Закон о статистике).
Также в этот период были приняты Федеральный закон “Об информации, информационных технологиях и о защите информации” от 27 июля 2006 г.; Федеральный закон “О персональных данных” от 27 июля 2006г.; Кодекс Российской Федерации об административных правонарушениях от 30 декабря 2001 г. и другие законы и нормативные акты Правительства Российской Федерации, касающиеся правового регулирования официального статистического учета в Российской Федерации.
Основной целью Закона о статистике является создание правовых основ реализации единой государственной политики в области официального статистического учета, направленной на обеспечение информационных потребностей государства и общества в полной, объективной, научно-обоснованной и своевременной официальной статистической информации о социальных, экономических, демографических, экологических и других общественных явлениях в Российской Федерации.
С его принятием получили правовое регулирование многие направления деятельности в сфере официального статистического учета, осуществление которых ранее было затруднено. Установлены правила, соответствующие международным принципам официальной статистики, принятым Статистической комиссией ООН (1994 г.), и механизмы их реализации.
Полный текст исторический справки вы можете прочитать на сайте Росстата.
- Цифровизация предоставления статистических данных
- Снижение отчетной нагрузки на респондентов
- Усиление координации статистической деятельности
- Удовлетворение потребностей пользователей и повышение доверия к официальной статистике
- Совершенствование статистической методологии
- Активизация международного сотрудничества
- Внедрение новых методов управления кадрами
- Оптимизация административных процессов в Росстате
- Реализация проектов национального значения
В частности, за счет цифровизации планируется к 2024 г.:
- сократить сроки сбора статистической отчетности в три раза посредством электронного сбора и перехода на потоковую модель сбора первичных статистических данных, формируемых респондентами в автоматизированных системах первичного учета и
- сократить сроки обработки первичных статистических данных и формирования официальной статистической информации в 1,5 раза.
Что касается задачи «удовлетворения потребностей пользователей и повышения доверия к официальной статистике», здесь немаловажно, что наши власти уже задумались о том, как повысить прозрачность и доступность официальных данных для широкой публики в классифицированном цифровом виде:
Разработчикам, общественным организациям, гражданам, журналистам, работающим в новом направлении – журналистике данных, в качестве основы для создания удобных и полезных приложений и сервисов необходима информация, размещаемая в форме открытых данных. Открытые данные, размещаемые в форме набора отдельных показателей, менее полезны и востребованы, чем логически увязанные последовательности (например, построенные в единой методологии временные ряды, ранжированные последовательности).
<…>
Потребуется обеспечить максимальную информационную открытость ведомства. Сегодня недостаточно производить и хранить имеющуюся статистическую информацию. Необходимо использовать все каналы взаимодействия с пользователями для популяризации статистики
и повышения статистической грамотности.
Отсюда постулируются и довольно-таки смелые плановые показатели 2024 г.:
- уровень удовлетворенности потребителей официальной статистической информации – 90 процентов;
- постоянное нахождение Росстата в ТОП-10 рейтинга Экспертного совета при Правительстве Российской Федерации по уровню развития механизмов (инструментов) открытости и направлений открытости;
- доля общедоступных показателей, раскрываемых в формате открытых данных, – 100 процентов.
Единый статистический ресурс — ЕМИСС
Сегодня вся статистическая информация, собираемая Росстатом, хранится в единой базе статистических данных — ЕМИСС, доступной на сайте www.fedstat.ru. По состоянию на момент написания этой статьи, база ЕМИСС содержит 7230 показателей, собранных от 65 государственных ведомств. На главной странице есть диаграмма, показывающая, что ежемесячно обновляется более 1000 показателей.
ЕМИСС представляет собой государственный информационный ресурс, объединяющий официальные государственные информационные статистические ресурсы, формируемые субъектами официального статистического учета в рамках реализации федерального плана статистических работ.
Доступ к официальной статистической информации, включенной в состав статистических ресурсов, входящих в межведомственную систему, осуществляется на безвозмездной и недискриминационной основе.
(С сайта ЕМИСС)
Для удобства несколько прямых ссылок:
ЕМИСС — довольно гибкая система, которая позволяет скачивать, искать и визуализировать любые данные любым пользователям без наличия регистрации и с расширенными настройками представления (классификация, сортировка, фильтрация и т.д.), а также поддерживает запись статистических данных в базу для пользователей с правами «Эксперта». Но поскольку мы с вами явно не «эксперты», наш удел — скачивание и использование готовых данных 🙂 О чем дальше и будем говорить.
Реестр показателей, наиболее популярные запросы
Реестр — информационный ресурс, включающий документы, дела и систему записей по установленной форме.
Реестр ведется по ряду сведений:
• форма статотчетности;
• единица измерения;
На сайте ЕМИСС статистика представлена по свыше чем 6400 показателям, количество может постоянно изменяться, в зависимости от требований, запросов.
К числу наиболее пользующихся популярность относятся:
- размер доходов, расходов различных категорий за 2019 год;
- импорт отдельных групп товаров;
- величина цен на услуги или товары;
- заработная плата по регионам;
- средние потребительские цены (тарифы);
- численность населения.
Пользуются популярностью запросы, связанные со здравоохранением, например, какая обеспеченность врачами на 10 000 человек населения, соотношение врачей к среднему медицинскому персоналу, запись к врачу, посещаемость без записи.
В заключение следует сказать, статистика — не просто разновидность деятельности, это прежде всего научный подход на основе анализа объективных процессов. Она изучает общество, анализируя динамику различных явлений, причины спада и роста, уровня стабилизации общества.
Многие определенные задачи решаются благодаря постоянному развитию применяемых методик, совершенствованию информационно-аналитических технологий. Создание единого ресурса — очередной шаг совершенствования НСО. Данные, полученные в результате изучения массовых проявлений методами статистики, составляют объективную базу других исследований в различных сферах, являются основой достоверности сделанных ими выводов.
Без статистики невозможно познание, расшифровка всех закономерностей как природных, так социальных явлений, невозможно их достоверно предугадать, следовательно, невозможно регулирование на всех уровнях — отдельного предприятия, региона, страны.
тел. +7 (495)3201019,
тел. 9 (800)1006042,
факс: +7 (495)9835964,
Итак.
Итак, мы завершили обзор решения, которое позволяет пользоваться официальными данными Росстата (покрывающими сотни различных аспектов жизнедеятельности нашей страны) без постоянного доступа к Интернету, «без email и регистрации», самостоятельно анализируя и препарируя данные в любом объеме и любыми инструментами. А поскольку рассмотренное решение на базе Python + PostgreSQL можно назвать
По крайней мере, с точки зрения кроссплатформенности. Но есть также решения, позволяющие запускать и пользовать PostgreSQL без установки. Я уж не говорю про различные дистрибутивы Python, которые также работают без классической инсталляции.
— название статьи нельзя ругать за чистый кликбейт 🙂
Еще раз ссылка на проект (Github)
Что обозначает ЕМИСС
В целях развития структуры, наиболее точно представлявшей сложившуюся в государстве и отдельных регионах, отраслях объективную картину на основе сбора сведений, совокупного, качественного анализа, было принято решение сформировать единый ресурс, координирующий деятельность, объединяющий все официальные статистические фонды. Независимо от района, сферы деятельности, ведомства отчеты, согласно утверждённым формам, срокам стекаются в общую базу, что позволяет проводить более глубокий, объективный анализ.
ЕМИСС расшифровывается так: Е – единая, М – межведомственная, то есть объединяющая информационные базы всех структур, собирающих и обрабатывающих статистическую информацию независимо от их ведомственной принадлежности, с целью воссоздания общей картины.
ИСС — информационно-статистическая система.
Системный анализ этих баз данных для предоставления информации о различных статистических показателях.
Задача ресурса — обеспечение свободного получения соответствующей информации различными органами (государственными, местного самоуправления), различными юридическими, физическими лицами. К примеру, статистической информации о среднедушевых доходах, уровне бедности, показателях поиска много. Получение информации, возможность ознакомиться со статистическими выкладками предоставляется бесплатно.
В своей работе система получает информацию от более 60 основных ведомств. Они законодательно обязаны предоставлять ЕМИСС сведения для обработки в установленные сроки.
Межведомственная система предоставляет услуги в онлайн-режиме, используя свой сайт.
Координатором деятельности выступает основная служба статистики – Росстат (gks.ru), оператором – Минкомсвязь России.
Клиентская часть
Как я уже говорил, клиент написан на Python (Python 3 или, если быть точнее, Python 3.9). Исходный код (включающий, кстати, и актуальный бэкап БД) доступен на Github.
Фронтэнд
Сразу оговорюсь, что работа над клиентом в части фронтэнда еще ведется. Окончательный вариант пользовательского интерфейса как таковой отсутствует на данный момент. Я пытался реализовать веб-приложение на Flask, но пока мои потуги уперлись в отсутствие опыта веб-разработки 🙂 Тем не менее, наработки доступны в ветке webapp, к которой, мне кажется, я еще вернусь. В идеале я планировал опубликовать полноценное веб-приложение на Heroku или Google App Engine, чтобы люди могли пользоваться без необходимости локального приложения и установки PostgreSQL. Как говорится, мне надо еще поучить «матчасть». Возможно, кто-то из вас сможет предложить какую-то другую идею или самостоятельно форкнуть проект и допилить интерфейс — смотрите сами!
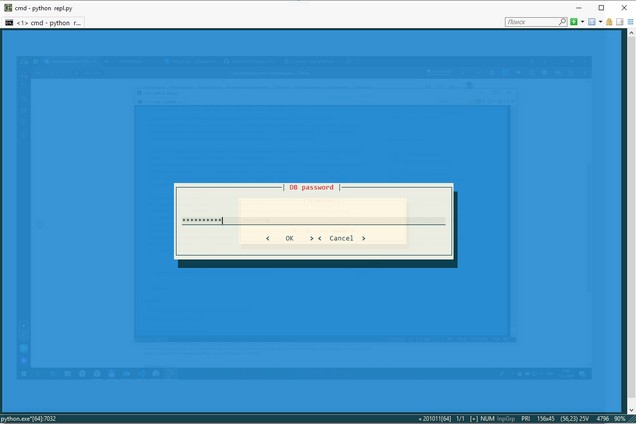
Ввод пароля БД при старте приложения
Ввод команд и панель подсказок внизу окна
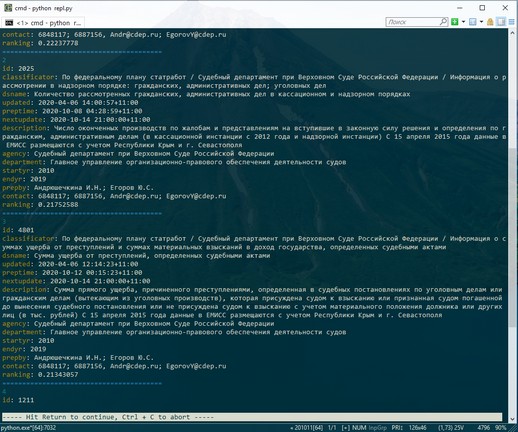
Последовательный вывод результатов поиска с форматированием
Отображение рубрик датасетов в иерархическом порядке
REPL пока также не завершен и еще допиливается (пока нет импорта / экспорта данных, реализации SQL-запросов и много еще чего), но концепция должна быть понятна.
Бэкэнд
Бэкэнд состоит из 3 модулей:
- rsengine — скачивание, парсинг и конвертирование данных ЕМИСС
- psdb — работа с базой данных PostgreSQL, в т.ч. поиск и вывод результатов в различных форматах
- russtat — основная входная точка программы, реализующая функции импорта данных из ЕМИСС в локальную БД и различные тесты
Также в состав приложения входит модуль globs.py с глобальными переменными и утилитами. В нем достойна упоминания переменная булевая DEBUGGING, которую можно использовать как флаг для включения и отключения подробных логов.
Модуль rsengine
В модуле rsengine определен единственный класс — Russtat, в задачи которого входит загрузка исходных датасетов и их реестра в формате XML с сайта ЕМИСС, обновление локального реестра датасетов в формате JSON, парсинг и конвертация данных в JSON с опциональным сохранением их в директории проекта (для последующего переноса в БД или иных целей).
Множественные операции (такие как скачивание и процессирование датасетов) выполняются параллельно в нескольких процессах при помощи multiprocessing.Pool, что значительно ускоряет работу. Детали реализации смотрите в исходниках, которые, кстати, я постарался сразу подробно документировать с созданием «человеческой» справки на Doxygen (см. в директории doc). Справка пока, правда, только на английском, но вас же это не смущает? 🙂
Модуль psdb
В модуле psdb определены два класса: класс Psdb, отвечающий за «низкоуровневую» работу с БД PostgreSQL, и унаследованный от него класс Russtatdb, который более конкретно заточен на работу с нашей локальной БД с учетом ее специфики, в частности, определенных в ней серверных функций.
В качестве движка для PostgreSQL используется psycopg2 (де-факто стандартный Python клиент для этой СУБД). В качестве альтернативы я пробовал также подход на основе ORM (PonyORM), но уперся в определенные трудности, связанные с отсутствием поддержки типа tsvector (напомню, это для полнотекстового поиска) в ORM. Любопытные могут посмотреть на мои «старания» в ветке ponyorm. Вообще же я для себя понял, что ORM — это не мое 🙂 Достаточно знания SQL и стандартного питоновского подхода к управлению БД (см. PEP 249, он же DB-API).
В классе Psdb определены, в частности, методы sqlquery и fetch, которые я постарался сделать достаточно мощными для любых запросов и возврата результатов в виде итератора («сырого» курсора БД), списка, словаря или датафрейма pandas.
В классе Russtatdb определены, в основном, методы поиска (по датасетам и наблюдениям), форматированного вывода результатов (в т.ч. для нужд REPL), а также импорта данных в БД (метод add_data). Этот последний метод, по сути, является оберткой вокруг серверной функции с тем же названием, о который мы уже говорили выше. Точно такими же обертками являются методы findin_datasets и findin_data, которые вызывают соответствующие функции поиска по шаблону в БД.
Модуль russtat
В модуле russtat, который содержит точку входа в клиентское приложение (вернее, одну из точек входа, так как другой является repl.py), основной функцией является update_db. Как следует из ее названия, она обновляет данные в БД: сначала при необходимости обновляется реестр датасетов с сайта ЕМИСС, затем скачиваются сами датасеты (можно указать диапазон и возможность пропуска уже существующих датасетов) и импортируются в БД при помощи метода add_data. Это делается, как я уже говорил, в мультипроцессовом режиме, с выводом промежуточных и финального логов (в консоль или указанный файл).
Таким образом, если у вас чистая (только что созданная) БД, то начать необходимо с вызова russtat.py (в аргументы командной строки можно передавать параметры обновления БД, но для чистой БД лучше все оставить по умолчанию, т.е. не передавать параметры).
